As businesses increasingly rely on software to deliver their products and services, ensuring that their production applications are running smoothly and efficiently becomes a must for maintaining what makes your app to be dependable on: application reliability, performance, and availability.
One critical aspect of monitoring production apps is measuring resource usage, including CPU, memory, and network utilization and that’s very well covered by many solutions. As previously mentioned, I particularly like The TLIG Stack for that. These metrics can provide valuable insights into the application’s health, allowing teams to identify performance bottlenecks and detect potential issues before they escalate into larger problems.
But what about when we want to not be blind about how resources are used by every instance of an app running on Pharo Smalltalk virtual machines?
When it comes to monitoring this, from the operations point of view, your Pharo images need to not be black boxes anymore. You need to have inner visibility on how the computing resources are used by your app in each of these VMs.
Enter Pharometer, a Zinc delegate for sampling Pharo metrics in a InfluxDB friendly format.
Pharo Smalltalk is a powerful and dynamic programming language that offers significant flexibility hence performance to grow features, but this can make it challenging to operate as you deploy versions because its resource usage could vary without you having a quick feedback loop about it. This creates a feedback gap. By monitoring the internal resource usage of every Pharo Smalltalk Virtual Machine, teams would close this feedback gap and more easily identify and resolve service performance issues, ensuring that their production applications remain fast, reliable, and available to users as any dependable service would.
When searching for what was already existing, I came across this nice blog post from Pierce Ng Telemon: Pharo metrics for Telegraf showing the idea of using TIG for collecting and displaying Pharo Smalltalk apps’ metrics.
Pierce’s article got me encouraged to do my own TIG setup, thank you Pierce! Although it was great at the beginning, I started to feel I needed to add a couple of missing parts for using it to operate production services: logs aggregation and querying and availability monitoring and alerts. After researching options, I’ve settled with Loki (fed by Promtail) and Kuma.
By the way, here you can see more on how to use docker-compose to have all that running in a server The TLIG Stack.
Open the hood
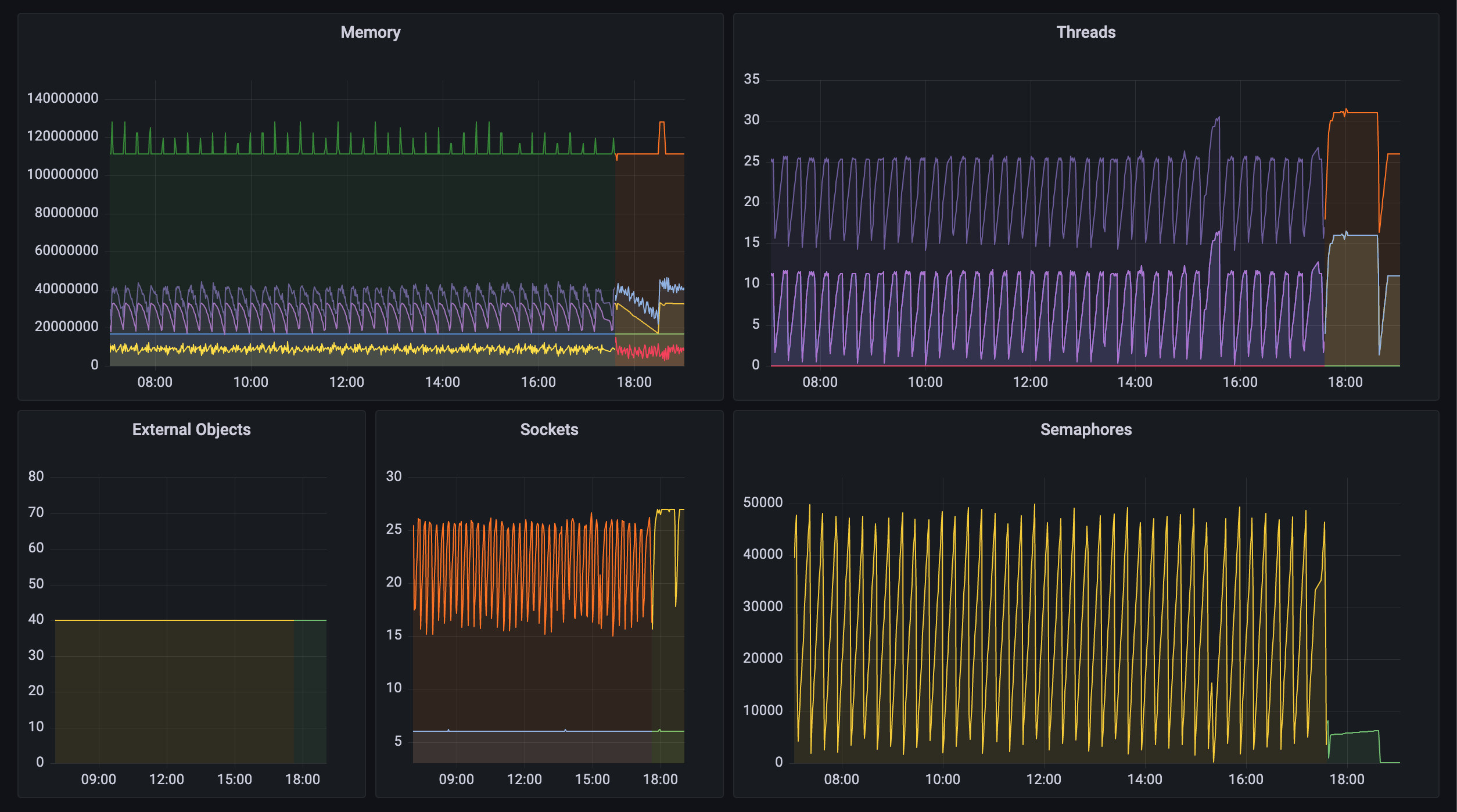
Once the basic monitoring with the TLIG stack is available, we can go to the next level and add a nice Grafana dashboard displaying what we can collect using Pharometer to see the performance details of running Pharo images.
You need two things for that to happen:
- Pharo images with your app responding values. This is solved using a customized
Pharometerin your running image. - Telegraf configured to periodically sample these values. This is satisfied by configuring a custom HTTP plugin in Telegraf.
Pharometer is a single class program designed to work as a Zinc delegate. It has a name, tags for labelling, fields (that you can think as label and measured value pairs), and a context that can be used to optimize “costly” calculations to aid during the rendering process. Is this context dictionary, the place where you can store a value that you can re-use in calculating the metric of more than one field without having to compute the costly value more than once.
Let’s see an example to understand its convenience.
Here, monitor Socket instances, we’re adding one context builder to count all the instances of the Socket class, which we can consider as a costly operation we want to do once:
| pharometer |
pharometer := Pharometer named: 'pharo'.
pharometer addContextBuilder: [ :ctx | ctx at: #sockets put: Socket allInstances ].
pharometer addTag: #app value: 'app-42'.
pharometer addTag: #image value: [ Smalltalk image imageDirectory pathString ].
pharometer
addField: #totalSockets
value: [ :ctx |
"Quantity of all Socket instances"
(ctx at: #sockets) size ].
pharometer
addField: #connectedSockets
value: [ :ctx |
"From all Socket instances, quantity of those which are connected"
((ctx at: #sockets) select: [ :e | e isConnected ]) size ].
pharometer
addField: #validSockets
value: [ :ctx |
"From all Socket instances, quantity of those which are in a valid state"
((ctx at: #sockets) select: [ :e | e isValid ]) size ].
The render method will create a new context by sequentially evaluating all the contextBuilder closures that you added (if any).
The previous example would grab all the current instances of Socket once and render these 3 measurements derived from it:
pharometer render.
"'pharo,app=app-42,image=/Users/seb/Developer/blah-project totalSockets=14,connectedSockets=4,validSockets=12'"
Pharometer is clean and doesn’t have any default values or tags. And yet, is flexible enough to be customized to serve whatever fresh measurements you make it calculate. All by efficiently consuming them during the rendering phase when the field closures get executed.
Although it’s clean, I’ve added some convenient presets methods that will add different categories of measurements. At least I wanted a way to keep an eye on sockets, memory, threads and "other" resources.
Note that, while addMemoryMetrics doesn’t make any use of the context builder:
addMemoryMetrics
self
addField: #freeSize value: [ Smalltalk vm freeSize ];
addField: #edenSpaceSize value: [ Smalltalk vm edenSpaceSize ];addField: #youngSpaceSize value: [ Smalltalk vm youngSpaceSize ];addField: #freeOldSpaceSize value: [ Smalltalk vm freeOldSpaceSize ];
addField: #memorySize value: [ Smalltalk vm memorySize ];
yourself.
addThreadMetrics makes a convenient use of it:
addThreadMetrics
self
addContextBuilder: [ :ctx |
ctx at: #processes put: Process allInstances ];
addField: #totalProcesses
value: [ :ctx | (ctx at: #processes) size ];
addField: #suspendedProcesses
value: [ :ctx |
((ctx at: #processes) select: [ :e | e isSuspended ]) size ];
addField: #terminatedProcesses
value: [ :ctx |
((ctx at: #processes) select: [ :e | e isTerminated ]) size ];
addField: #terminatingProcesses
value: [ :ctx |
((ctx at: #processes) select: [ :e | e isTerminating ]) size ];
yourself
Putting it all together
If you don’t have yet custom metrics you want to sample, here is a handy setup that will measure basic VM resources usage for you:
| pharometer zincServer |
pharometer := (Pharometer named: 'pharo42')
addMemoryMetrics;
addSocketMetrics;
addThreadMetrics;
addOtherMetrics;
yourself.
zincServer := ZnServer on: 8890.
zincServer delegate: pharometer.
zincServer start.
With this as part of you app build and startup process, all that is left is to consume it. When using the TLIG stack, this is done with a generic Telegraf HTTP plugin.
If you use the TLIG stack from this repository, you’ll find a conf/telegraf/telegraf.conf file that is a massive yml file.
To add the plugin that would sample your Pharometer measurments, search for Read formatted Pharo metrics from an HTTP endpoint and all you need to do there is to tell, in which URL, Pharometer is rendering that output
In this example, it’s using http://host.docker.internal:8890\" because that TLIG stack runs using docker-compose and host.docker.internal is a way to make it find when your Pharo app is reachable from the host. Have in mind this good for a starter setup but this will vary depending on how you deploy and how complex your deployed targets are.
Here is a sample of a Telegraf working HTTP plugin:
# Read formatted Pharo metrics from an HTTP endpoint
[[inputs.http]]
## One or more URLs from which to read formatted metrics
urls = [
"http://host.docker.internal:8890"
]
## HTTP method
method = "GET"
A pending follow up to this setup is find a way to conveniently setup Telegraf to monitor a bunch of Pharo Smalltalk running images and make a overview dashboard for a cluster and a per-Pharo dashboard when you want to drill down and check its performance details.
I hope that by now you have a better sense of how to monitor services that are built on top of Pharo Smalltalk applications in production and that Pharometer, as a Zinc delegate, can provide valuable insights into the application’s health by measuring resource usage.
Looking forward to see people sharing Grafana dashboards customized and useful to other people running Pharo based services.
Have a happy Grafana dashboarding process based on TLIG and Pharometer!